Build a (Tiny) LLM from Scratch
Why Learn How LLMs Work?
Large language models are everywhere. ChatGPT writes code, answers questions, and generates content. GitHub Copilot completes your functions. Every tech company is integrating AI into their products. LLMs have become infrastructure, like databases and APIs.
Yet most developers treat them as black boxes - call an API, get a response, hope it works.
This creates a problem. When you don't understand how something works, you can't debug it, optimize it, or build on top of it effectively. When the API returns gibberish, you don't know why. When latency is too high, you can't fix it. When you need custom behavior, you're stuck.
Learning how LLMs actually work changes everything. You'll understand why they hallucinate, why temperature affects output randomness, why context length matters, and how to architect systems that use them effectively.
The Learning Problem
Most LLM explanations assume machine learning knowledge. They throw around terms like "self-attention," "learned positional encodings," and "gradient descent" without explanation. Research papers are impenetrable. Tutorials skip fundamentals. You're either a PhD or you're lost.
This is the transformer architecture from "Attention Is All You Need", the 2017 paper that started it all:
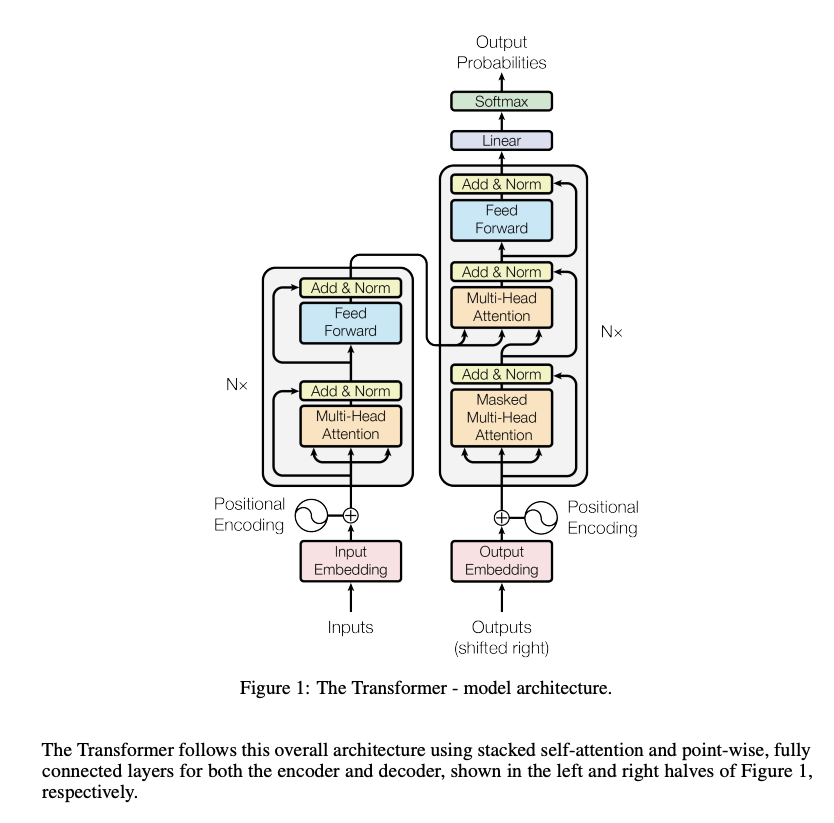

When I first saw this diagram, I understood nothing. Multi-Head Attention? Positional Encoding? Add & Norm? Feed Forward? Every box assumed knowledge I didn't have. The paper explained each component using more terminology I didn't know. I wanted to understand how transformers worked, but every explanation pointed me to this diagram and told me to "just read the paper."
That frustration is why this course exists. You shouldn't need a machine learning PhD to understand the technology reshaping software development. This course breaks down that intimidating diagram into a clear learning path:

This course assumes zero ML knowledge. If you can write code and understand basic math, you can learn this. We build from first principles: text becomes numbers, numbers flow through mathematical operations, operations stack to create a transformer.
What You'll Build
By the end of this course, you'll build a working language model from scratch - a minimal transformer that generates text. Yes, a "small LLM" is technically an oxymoron (the L stands for Large), but ours is intentionally tiny - just 20 words in its vocabulary:
the, cat, dog, sat, ran, on, mat, house, a, big, small, quickly, slowly, and, is, red, blue, to, PAD, END
With these 20 words and carefully designed training patterns, your tiny GPT demonstrates genuine transformer capabilities:
- Long-range attention: "the big cat sat on the" → "big mat" (remembers size from 6 words back)
- Selective attention: "the red big cat sat on the" → "big mat" (ignores color, attends to size)
- Context awareness: "the cat and the" → "dog" (prefers variety over repetition)
- Pattern completion: "the small dog ran to the small" → "house" (completes size-matched pattern)
- Multi-word generation: Generates coherent sequences autoregressively, one token at a time
This tiny GPT uses the same core building blocks as GPT-4, scaled down to run in your browser. It has 4-head attention, layer normalization, GELU activation, feed-forward networks, residual connections, and causal masking - the fundamental components of any transformer. GPT-4 has many more layers (rumored to be 120+), thousands of attention heads, and likely additional architectural refinements. But the core principles remain the same. Every component you'll implement yourself using NumPy. You'll understand not just how to use transformers, but how they work at a fundamental level.
What the Model Learned From
The behaviors you just saw aren't programmed - they emerged from training data. The model learned from carefully designed patterns that demonstrate transformer capabilities.
Pattern 1: Size Matching (Long-range Dependencies)
Training examples: "the big cat sat on the big mat" "the small dog ran to the small house" "the big dog sat on the big mat" "the small cat ran to the small house" ... (64 total variations)
The model learned: big animals use big objects, small animals use small objects. This teaches attention to look back and remember "big" from 6 words earlier.
Pattern 2: Color as Distractor (Selective Attention)
Training examples with color+size: "the red big cat sat on the big mat" ← color present, size matters "the blue small dog ran to the small house" Training examples with only color: "the red cat sat on the mat" ← no size, no pattern "the blue dog ran to the house" ← color doesn't predict "the red cat sat on the house" ← red doesn't mean mat
The model learned: color appears in sentences but doesn't predict outcomes. Size does. This teaches attention to ignore irrelevant features.
Pattern 3: Variety over Repetition (Context Awareness)
Training examples: "the cat and the dog" ← variety (5× more common) "the dog and the cat" "the cat and the cat" ← repetition (1× less common)
The model learned: when coordinating with "and", prefer different animals. This teaches attention to track earlier mentions.
These patterns repeated during training until the model's weight matrices adjusted to predict them accurately. The attention heads specialized: some learned to focus on size, others learned to ignore color, others learned to track coordination. Nobody programmed these specializations - they emerged from the data.
What You'll Gain
After this course, you'll understand transformers deeply enough to use them effectively in production.
Read research papers. You'll understand "Attention Is All You Need", the 2017 paper that started the transformer revolution. Every component - scaled dot-product attention, multi-head attention, positional encoding, layer normalization - will make sense because you implemented it yourself. Architectural jargon like "8-head attention with 512-dimensional keys" or "pre-norm vs post-norm" becomes clear rather than mysterious.
Debug LLM applications. When ChatGPT repeats itself, you'll know why (attention weights favoring recent tokens). When outputs are incoherent, you'll know what to adjust (temperature, top-k sampling). When context limits are hit, you'll understand the constraint (fixed positional encodings).
Make informed decisions. Choose between models based on actual capabilities, not marketing. Understand trade-offs: more layers = better quality but slower inference. More attention heads = better parallelization but more memory. You'll stop guessing and start reasoning.
Build better systems. Optimize token usage by understanding tokenization. Write better prompts by understanding pattern completion. Architect systems that work with transformers' strengths instead of fighting their constraints.
Most importantly: you'll stop treating LLMs as magic boxes. You'll understand the mathematics, see the patterns, and know exactly what's happening when a model generates text.
Prerequisites
This course assumes basic programming knowledge and comfort with Python. You don't need machine learning experience - we explain everything from first principles.
You should know how to write functions, use loops, and work with lists and dictionaries in Python. You should understand basic math like multiplication, addition, and what an average means. You should be comfortable reading code and following logical steps. If you've written a web server or built a database-backed application, you have more than enough background.
You don't need to know linear algebra, calculus, statistics, or probability theory. You don't need experience with PyTorch, TensorFlow, or any ML frameworks. You don't need to understand neural networks, backpropagation, or gradient descent. We'll teach you everything you need as you need it.
We use NumPy for implementations because it's explicit and clear. You'll see exactly what each operation does - no magic hidden in framework abstractions. Production transformers use PyTorch or JAX for efficiency and automatic differentiation, but the concepts are identical. Once you understand the NumPy version, picking up PyTorch is straightforward.
The Journey Ahead
This course progresses from text to working code. Each module builds on previous ones, introducing concepts exactly when you need them.
Module 1: From Text to Numbers - How LLMs convert text into numbers. You'll learn tokenization, embeddings, and vector similarity. By the end, you understand how "The cat sat" becomes mathematics the model can process.
Module 2: Predicting the Next Word - The fundamental operations that transform embeddings into predictions. You'll learn matrix multiplication, softmax, and build a simple next-word predictor. This predictor won't understand context yet, but it demonstrates the basic prediction pipeline.
Module 3: Attention Mechanism - Adding context awareness. You'll learn how attention compares every word to every other word, measuring which words should influence each other. This is the breakthrough that made modern LLMs possible.
Module 4: The Transformer Architecture - Assembling everything into a complete transformer. You'll learn feed-forward networks, layer normalization, non-linearity, and how to stack transformer blocks. You'll implement autoregressive text generation with temperature sampling. This is where your tiny GPT comes to life and generates coherent text.
Module 5: Training the Model (Coming Soon) - How the model learns from data. You'll understand backpropagation, loss functions, and why training costs millions of dollars while inference is cheap.
The next article starts your journey: understanding what large language models are and what they can (and can't) do. From there, you'll progressively build up to a complete working transformer.