Coding Interview Patterns: Your Personal Dijkstra's Algorithm to Landing Your Dream Job
The goal of AlgoMonster is to help you get a job in the shortest amount of time possible in a data-driven way. We compiled datasets of tech interview problems and broke them down by patterns. This way, we can determine the most frequently tested and highest return on investment (ROI) area to focus on. We'll look at the breakdown for top problems overall and company-specific investigations.
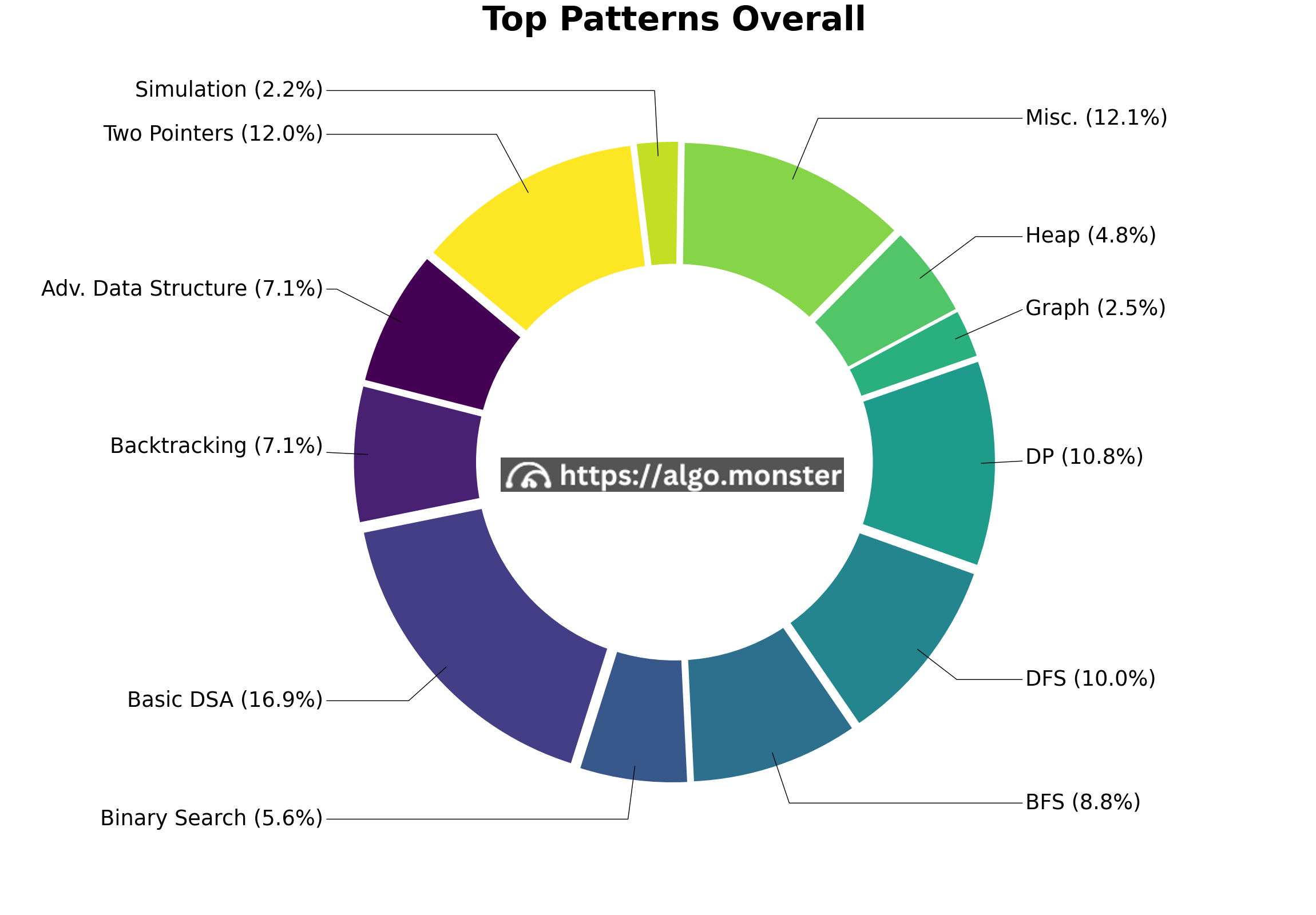

What to study to maximize your ROI
We created an ROI table based on the above analysis for your reference.

If you would like a video overview of the patterns, you can watch this video:
Highest ROI: DFS, BFS, Two pointers
Depth-first search(DFS), breadth-first search(BFS) and two pointers, make up a good portion of all interview problems. DFS in particular can be used to solve a wide range of problems from tree to graph to combinatorial problems and is very useful in tech interviews. We have a detailed explanation on each of these topics.
Basic Data Structures and Algorithms (DSA)'s have very high ROI
Basic DSAs include: Linked List, Array, Hash Map, Stack, Queue, Sorting.
Mastering these concepts will get you through most easy coding interviews. There also aren't many variations within each topic. For example, the linked list category has several classic problems such as reversing a linked list, finding the middle node of a linked list, and linked list cycle detection that get asked repeatedly. Many of these basic DSAs are also used in day-to-day coding tasks. Most people who have a good amount of coding experience should already be familiar with these concepts. Therefore we will spend less time on these topics.
Priority Queue/heap has medium ROI
Priority queue and heap show up surprisingly more often than most would think. The classic problems include the median of a data stream, k closest points.
Greedy, Dynamic Programming
Dynamic programming (DP) is hard to summarize and does not frequently appear (unless you are interviewing Google, whose engineers like to ask DP problems). There are a few classic problems you may want to know such as house robber and robot paths. Otherwise, you should probably focus on higher ROI areas if you are short on time. Also, if you can't figure out a dynamic programming solution, you can always do DFS + memoization which does the same thing.
Each greedy problem is different, and it's hard to summarize a pattern. The correctness of your solution often requires rigorous mathematical proof, which is hard to learn in a short time. Therefore, we consider greedy problems to be of low ROI.
Advanced data structures like trie and union find
These don't appear often but they do show up. Consider them of secondary priority.
Company-specific Trends
Amazon

Amazon's interview problems haven't changed much since the Cracking the Coding Interview days. Two-pointers, DFS, and BFS make up half the problems. Since the existence of the performance improvement plan, it's relatively easy to fire employees. So the interviews are not intended to be very difficult.
Meta
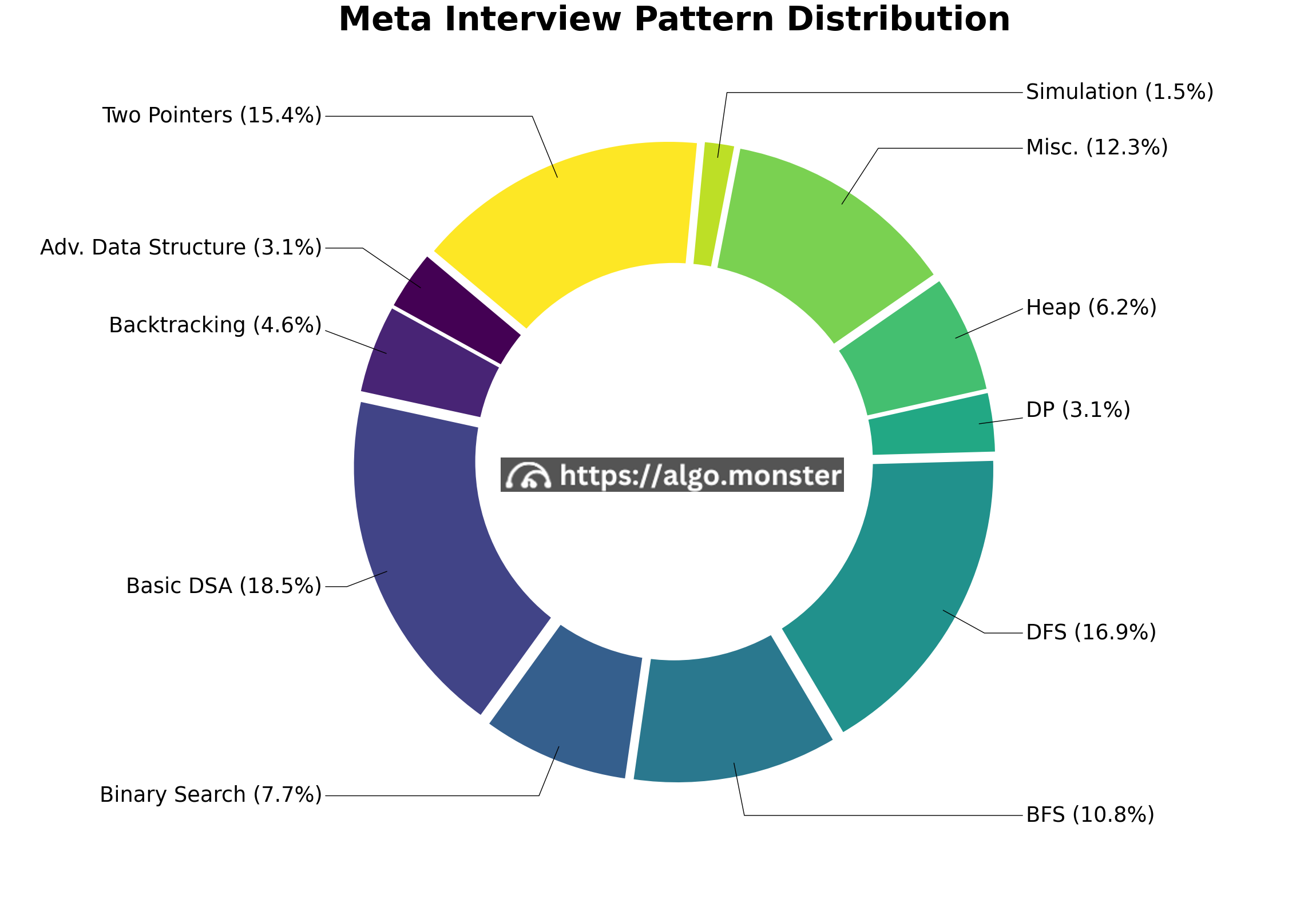
Meta likes to ask classic problems and is generally slightly more challenging than Amazon. Word on the streets is that the company cares more about bug-free coding than anything else. Two-pointers, DFS, and BFS still dominate. If you are interviewing Meta, it's good to practice the classic problems we have in this course multiple times.
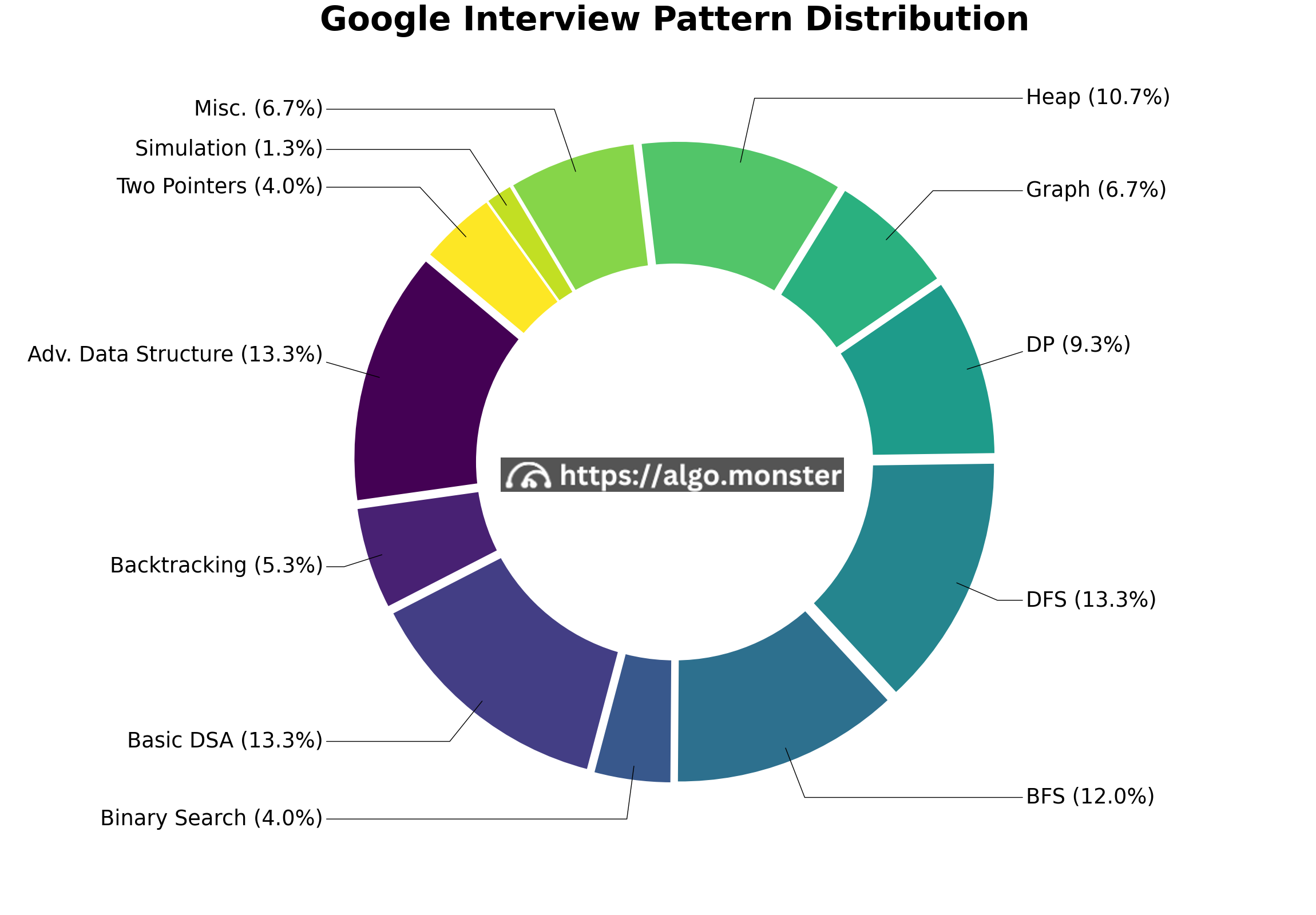
Google has an internal policy of not using any problem found on the internet for interviews. Therefore, the engineers constantly reinvent new problems, making the interview more difficult (or easier depending on how you view it since invented problems are often as well-thought-out as classic problems). Some problems require more than one pattern, e.g., prefix sum + binary search, DFS + prefix sum. You have to be very familiar with the basic patterns we have in this course.
20th Century Blue Chips like Oracle, IBM, Expedia
Companies like Oracle, IBM and Expedia have a fixed set of problems and don't usually update them. If you master the patterns we teach in this course, you should be able to solve them with ease.
Unicorn Startups
Unicorn startups like Airbnb, Uber, and Dropbox have a relatively stable problem bank compared to Google, and the problems are more challenging than Amazon. Classic patterns like DFS, BFS, two pointers are still the favorite. You may need to know Trie and union-find, too.
More companies
For more companies, explore the comprehensive company-specific interviews (actively updated). Each company guide includes:
- Overview of the company and interviewing process
- Patterns and difficulty distribution (large companies)
- Frequently asked coding questions
- Sample behavioral questions
These features are designed to give you a well-rounded preparation experience tailored to the company you're targeting.
A Note On Academic Algorithms
We use the term "academic algorithms" to mean algorithms that are taught in university textbooks and are not tested often, if ever, in real-world tech interviews, according to our statistics. A good-enough rule of thumb is an algorithm named after a person(s) you can safely ignore.
Very rarely/almost never used list:
- Minimal spanning tree: Kruskal's algorithm and Prim's algorithm
- Maximum flow: Ford−Fulkerson algorithm
- Shortest path in weight graphs: Bellman−Ford−Moore algorithm
- String search: Boyer−Moore algorithm
Knuth−Morris−Pratt (KMP) algorithm helps solve string problems, but interviewers will NOT expect to know how to do this. Typically bug-free brute force coding is required instead of KMP.
Dijkstra's algorithm helps find the shortest path between nodes in a weighted graph. Weighted graphs interview problems exist but are rare. It's good to have a high-level understanding of this algorithm since it uses a priority queue that frequently gets asked.
Rabin-Karp rolling hash algorithm is sometimes helpful in solving some two-pointer issues.
Does This All Sound Like Gibberish?
Don't know what a linked list is? Not sure how a hash table works? This guide assumes you're already familiar with basic data structures like arrays, strings, linked lists, stacks, queues, and hash tables. If that's not the case, start with our Foundation Course first.
The Foundation Course assumes zero knowledge of data structures - you just need to know basic programming (variables, loops, functions). It's laid out to teach you incrementally, building each concept on top of the previous one. Once you complete it, you'll have a solid foundation to come back here and tackle the core interview patterns with confidence.
Next Step: Get Your Personalized Study Roadmap
Get your study roadmap to see where you stand and get a personalized study roadmap to maximize your ROI.