Embeddings—Giving Tokens an Address in "Thought Space"
Tokens are the bricks, but how does the LLM "understand" them? Enter embeddings: fancy numerical representations that turn tokens into points in a vast "meaning map."
Let's build this from zero:
-
First Principle – Vectors as Coordinates: An embedding is a list of numbers (a vector) that works like GPS coordinates for a token’s meaning. Not just 2D, but hundreds or thousands of dimensions.
-
Golden Rule – Similarity = Closeness: Words with related meanings have nearby vectors. Example: in 4D space, cat = [0.5, -0.2, 0.8, -0.4], dog = [0.6, -0.1, 0.7, -0.3]—close together because they’re similar.
-
Why High-Dimensional? More dimensions capture subtleties, like “bank” (river) vs. “bank” (finance). Small spaces (2D, 4D) can’t separate meanings well. Typical models use embeddings with 768 dimensions in GPT-2 or 12K dimensions in GPT-3.
Word embeddings turn words into vectors of numbers. In the picture, each word (apple, banana, king, queen) is represented as a 2D point. Similar words end up closer together—apple and banana are near each other, just like king and queen. In practice, embeddings have many dimensions, but this 2D example makes it easy to visualize.
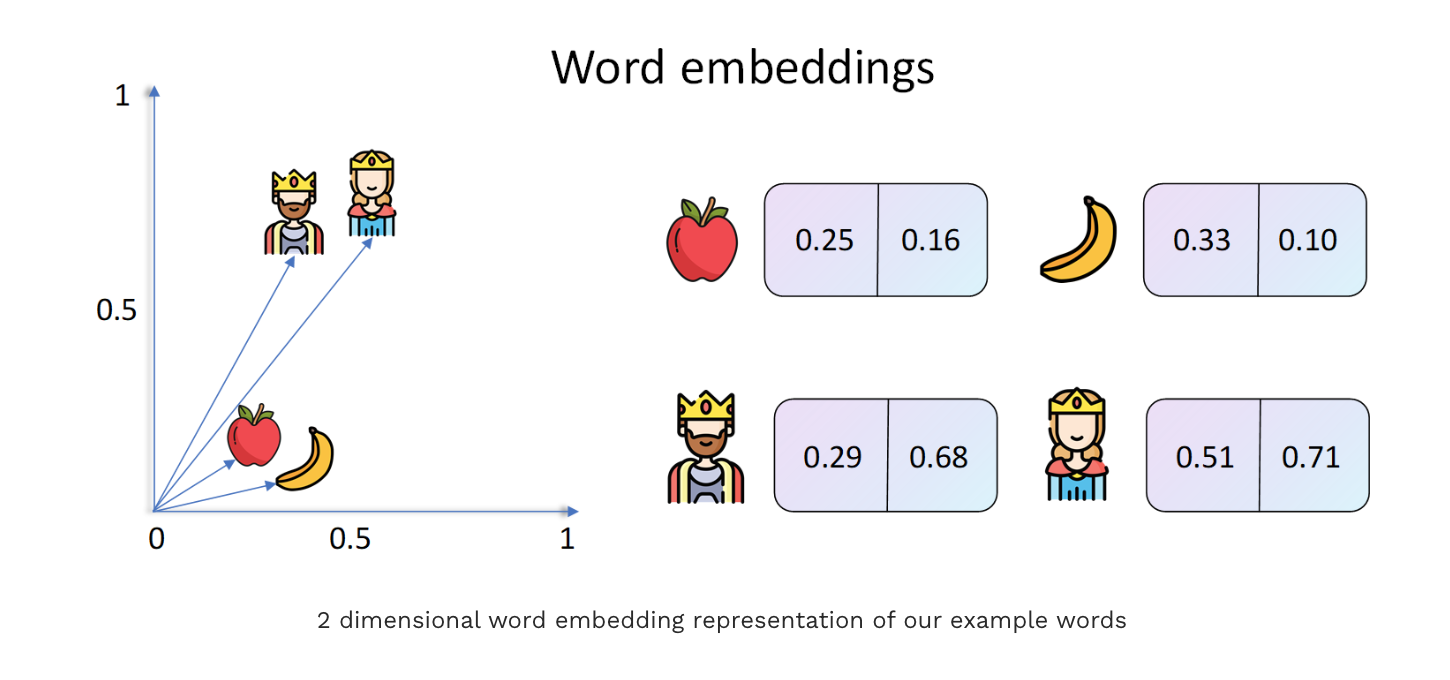

Reference Image from towardsDataScience.com.
Embeddings also enable "semantic math" because words are numerical vectors. This means we can perform arithmetic operations on them that reveal meaningful relationships.
Take the example: King - Man + Woman ≈ Queen.
- King is a vector.
- Subtracting the Man vector removes the male component of "king."
- Adding the Woman vector then imbues it with the female gender.
- The result is a vector very close to Queen.
This demonstrates that embeddings capture deep, nuanced relationships, crucial for LLM applications like:
- Analogy completion: (e.g., "Paris is to France as Berlin is to ____")
- Recommendation systems: Finding similar items.
- Cross-lingual understanding: Recognizing shared meaning across languages.
This ability to perform arithmetic on meaning, within a high-dimensional semantic space, allows LLMs to "reason" about language powerfully.