The Core Principle—It's All About Predicting the Next Word
Now that you've got the "what," let's uncover the "how" without overwhelming you. We'll go from simple ideas to the bigger picture.
-
First Principle: Sequence Prediction: At its heart, an LLM does one deceptively simple thing: Given a sequence of words, predict what comes next. That's it!
- Example: If I give it "The sky is...", it might predict "blue" because that's a common pattern in its training data. But it can handle way more complexity, like continuing a story or writing code.
-
Building the Model: During training, the LLM sees trillions of word sequences and learns probabilities. "After 'hello,' what's likely? 'world' or 'there'?" It builds a statistical map of language relationships.
-
Emergent Abilities: This simple prediction trick, when scaled up, leads to amazing "emergent" skills—things the model wasn't directly taught but can do anyway, like translating languages, summarizing articles, or even debugging code.
Analogy Escalation: Your brain does this too! When someone says, "Knock knock," you instantly think "Who's there?" because of patterns from jokes you've heard. An LLM is like a brain on hyperdrive, predicting not just one word, but entire paragraphs based on endless examples.
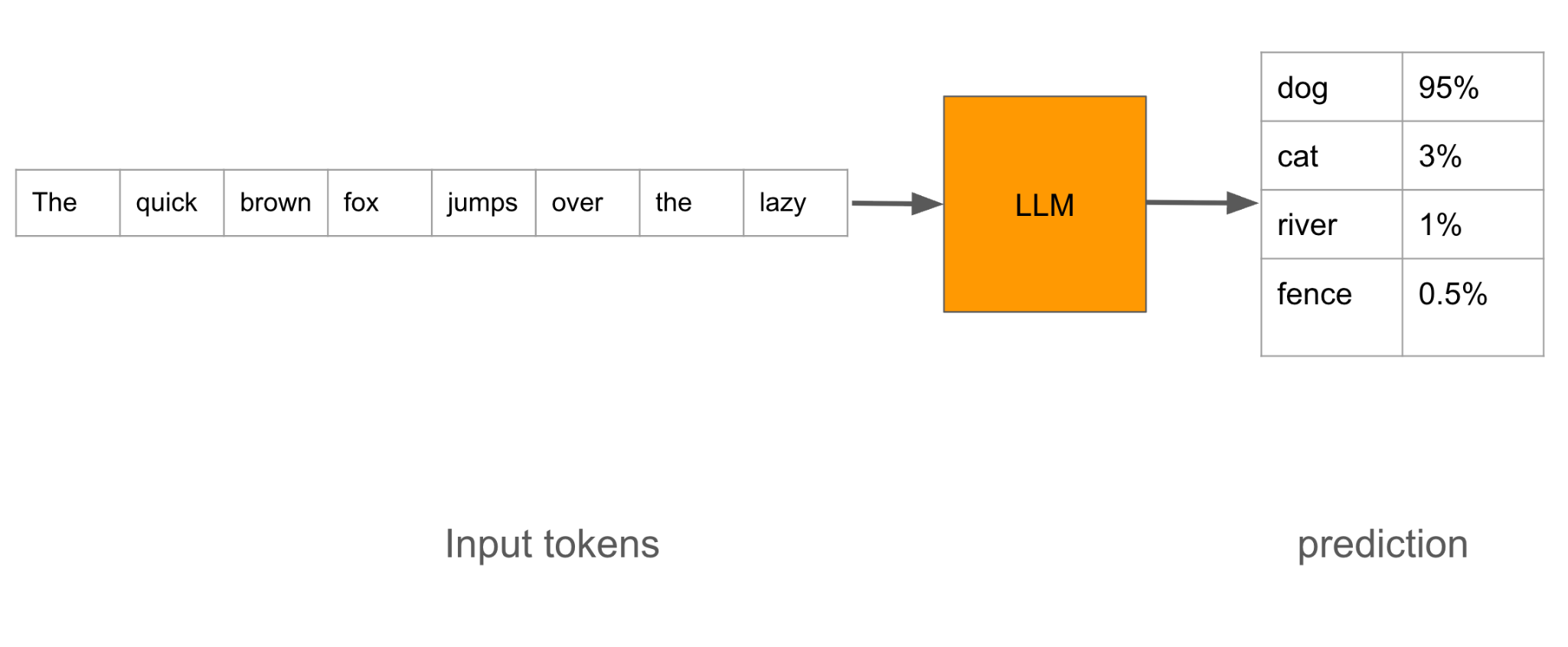

In the above example, we give the LLM the text “the quick brown fox jumps over the lazy.” It scores possible next words based on its training data. “dog” has the highest probability.
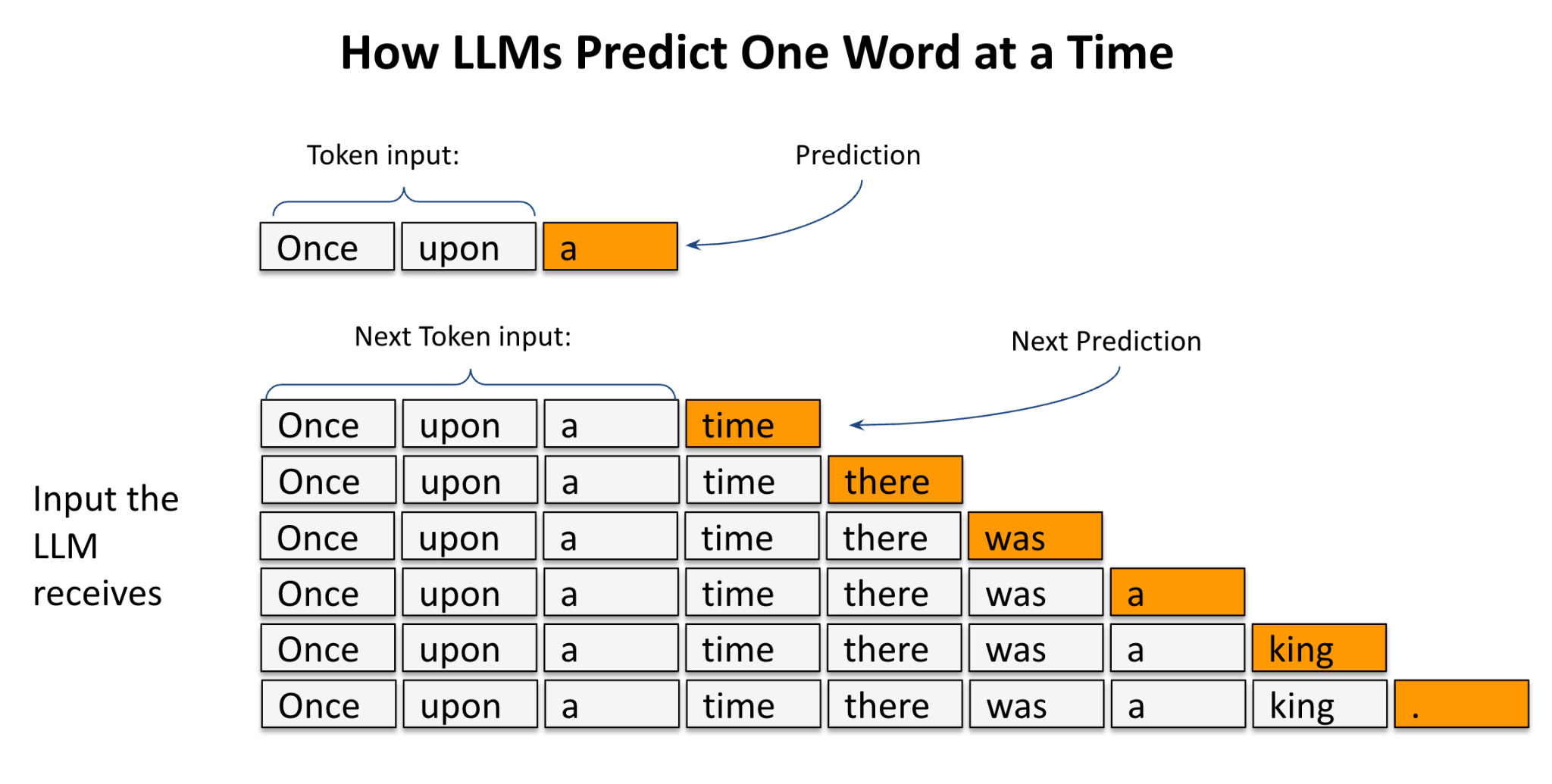
LLM generates text step by step by predicting one token at a time. Let’s look at a different example. Let’s say the model start receiving the sentence “Once upon”. It predicts the next likely word, which is “a”. That new token is then added to the input sequence, so the model now sees “Once upon a” and predicts the next word, “time”. This process repeats: the model keeps taking everything it has generated so far as input, and then predicts the next token. Highlighted tokens in orange show each new prediction added to the sequence. By continuing this iterative loop, the model builds a complete sentence such as “Once upon a time there was a king.” This illustrates the fundamental mechanism of LLMs: autoregressive next-token prediction.
Gradual Intuition Build: Start small—think of autocomplete on your phone. That's a mini-LLM predicting your next word. Now scale it: Add more data, more parameters, and suddenly it's writing essays or code. See how the basics lead to power?