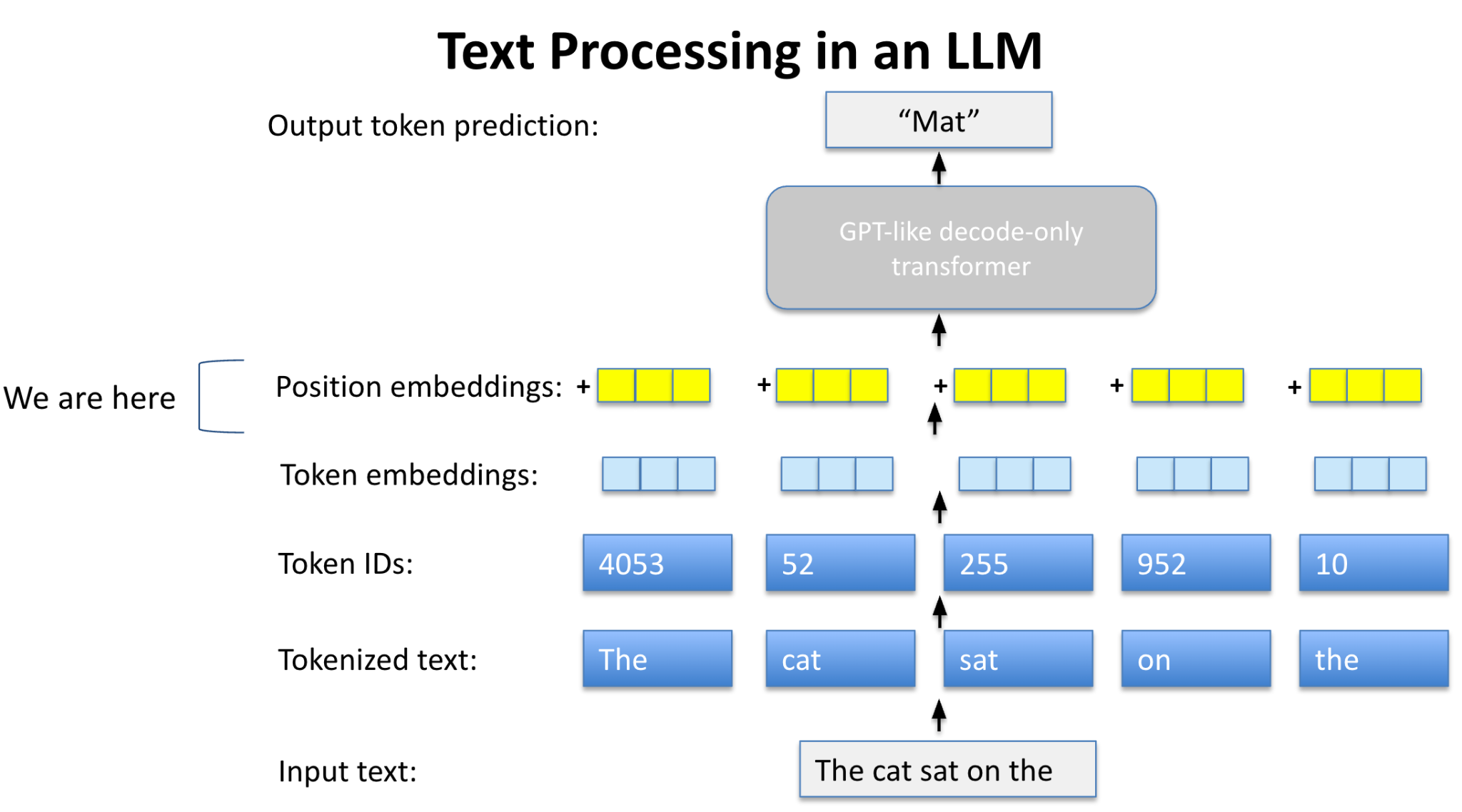
Giving the Model a Sense of Order - Positional Encoding
Transformers process all words in parallel (at the same time), which is efficient but creates a snag: Without order, "The cat chased the dog" looks the same as "The dog chased the cat." Order matters!
Let's build this understanding step by step:
-
First Principle: Sequences Need Structure: From Module 2, words are vectors. But vectors alone don't carry position info—like shuffled puzzle pieces.
-
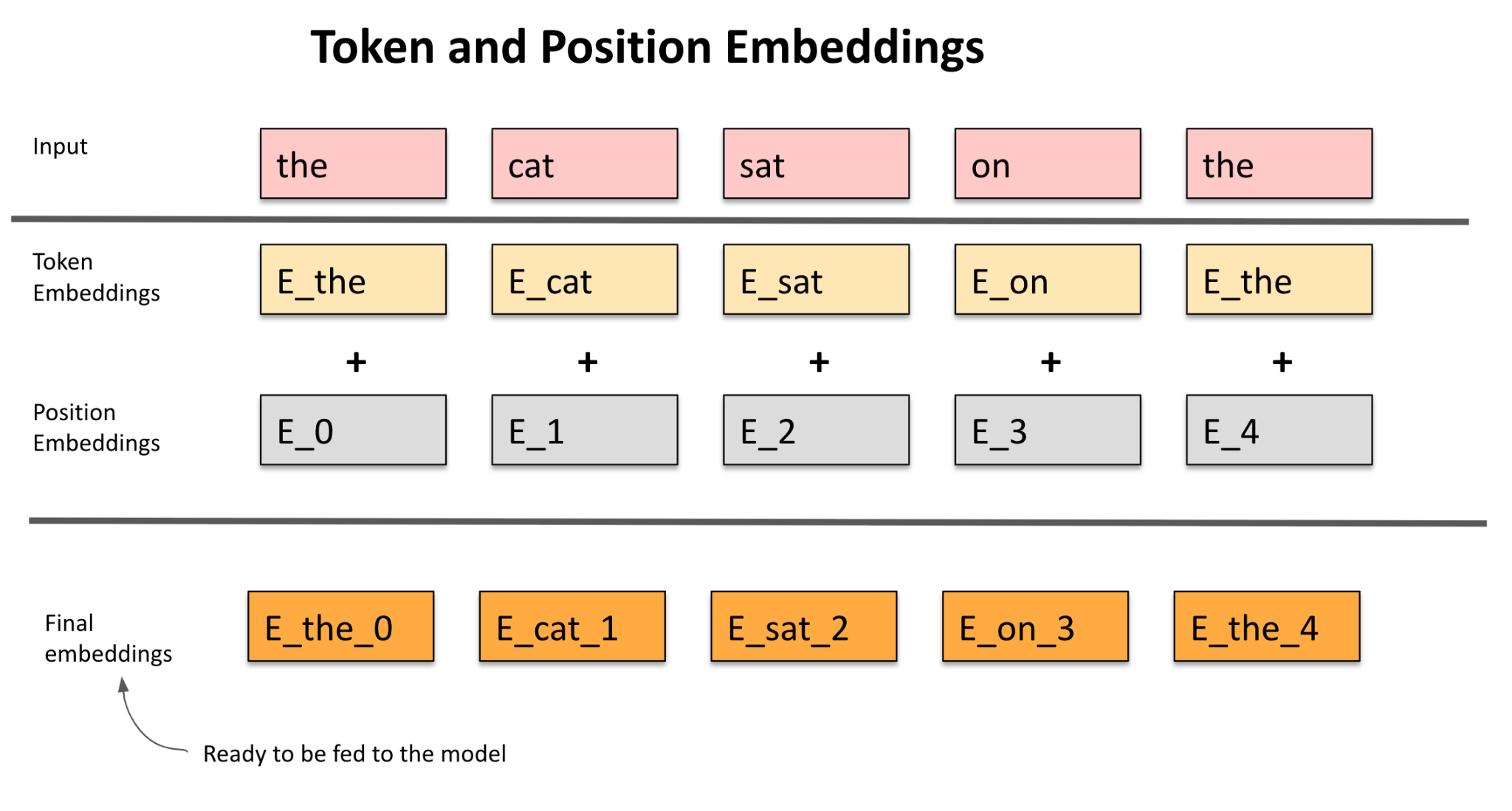
The Fix: Positional Encoding: Add a special vector to each word's embedding that encodes its position (1st, 2nd, etc.). It's like stamping a "page number" on each piece.

Analogy Escalation: Tear pages from a book and scatter them. Without numbers, no story flow. Positional encoding renumbers them invisibly, restoring sequence without changing content.
Gradual Intuition: Start small—number words in a sentence: "The (1) cat (2) sat (3)." Add that to embeddings, and the model "feels" the order in its math. Scale up, and it handles paragraphs or books.