The Feedforward Network (The 'Thinking' Step) | LeetCode / OA Coding Interview Solution
Okay, so the model has used attention to gather context for each word. It now has a rich, context-aware vector for every token. But gathering information isn't the same as understanding it. The next step is to actually process or "think" about this newly gathered context.
To do that, the Transformer uses a component called a Feedforward Neural Network. Before we explain what it does, let's quickly cover what a neural network is at a very high level.
A Quick Intro to Neural Networks (NNs)
Don't let the name intimidate you. At its core, a neural network is simply a tool for transforming numbers in a useful way.
Imagine a simple machine with a set of dials. You feed it a number (an input), it turns its dials, and a new number comes out (an output). A neural network "learns" by figuring out the perfect way to set those dials to turn inputs into the desired outputs consistently.
-
Layers: Real neural networks stack these dial-turning steps into "layers." The output from the first layer of dials becomes the input for a second layer, which has its own set of dials, and so on. Stacking layers allows the network to learn much more complex transformations.
-
Analogy: The Expert Assembly Line: Think of an assembly line.
- Input: Raw materials arrive (your context-rich word vector).
- Layer 1: The first station performs a specific task, like shaping the material.
- Layer 2: The second station takes the shaped material and does something else, like painting it.
- Output: A finished, more refined product comes out the other end.
A neural network is just an assembly line for information, with each layer transforming it a bit more.
The Feedforward Layer: Thinking About Each Word
The feedforward network inside a Transformer is a simple, two-layer version of this assembly line. After the attention mechanism has collected relevant information for a word, this context-rich vector is sent to its own personal feedforward network.
You can think of this as the "thinking" step: attention collects information from across the sentence, while the feedforward layer processes that information for each word individually.
Here’s how its simple "assembly line" is structured:
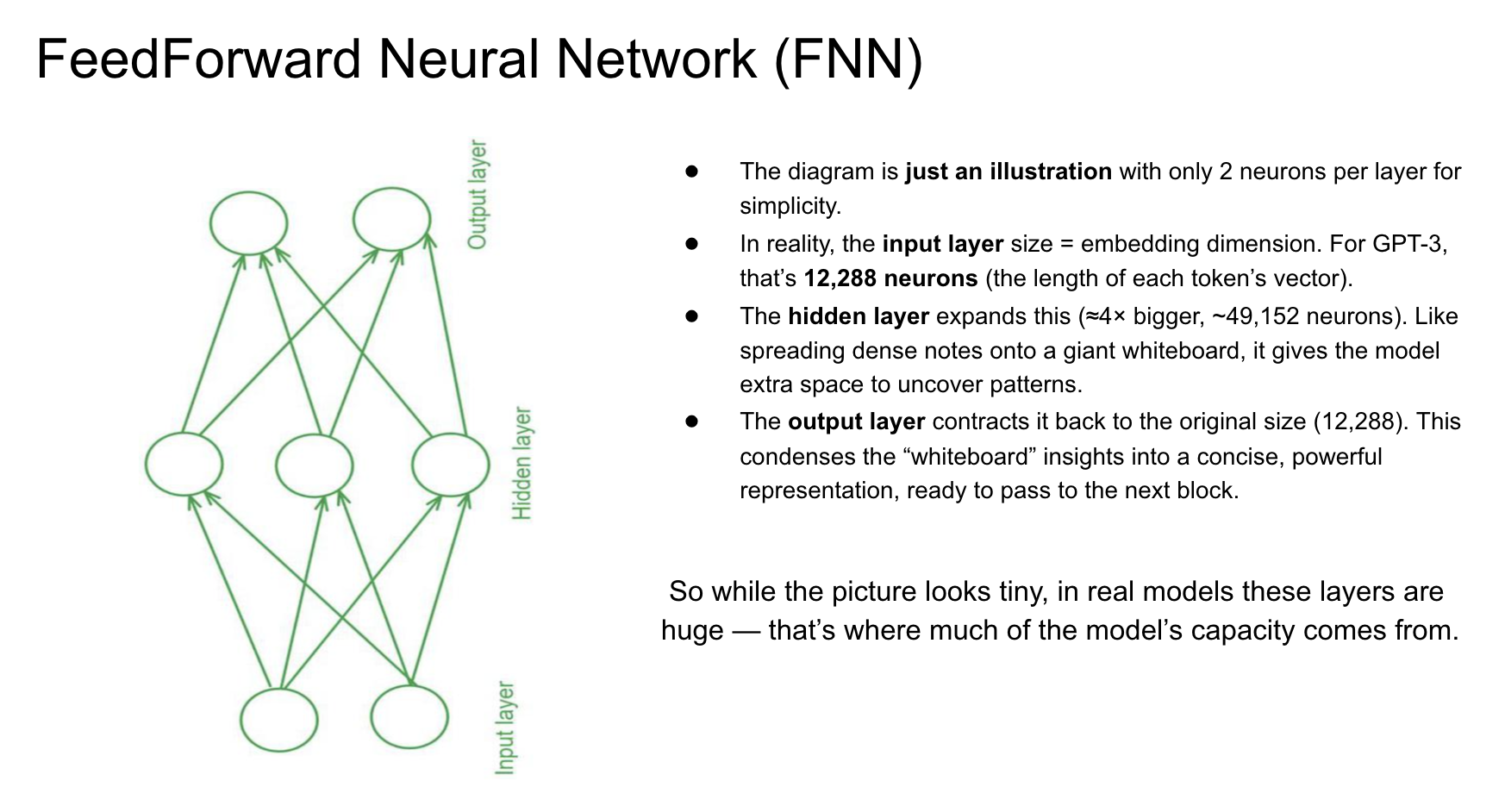
- Input layer: The attention-enriched vector for a single token (size = embedding dimension).
- Hidden layer (Expansion): The network expands the vector (often ×4). Like taking a dense paragraph of notes and spreading it across a giant whiteboard, this gives the model more "workspace" to discover complex patterns.
- Output layer (Contraction): The network shrinks the vector back to its original size. The key insights from the "whiteboard" are distilled into a concise, powerful representation—like summarizing brainstorm notes back into a sharp paragraph.

Why does this matter?
Attention is great at mixing information between different words. The feedforward layer's job is to process that mixed information within the representation of each single word. It helps the model build a deeper, more abstract understanding.
This combination of attention (gathering) + feedforward (thinking) makes up one complete Transformer block. And as we'll see next, this block gets repeated many, many times.
Analogy Recap: The Expert Consultant
- Gather (Attention): A team of researchers gathers a vast amount of data from a library and organizes it into a research brief.
- Think (Feedforward Layer): They hand this brief to an expert consultant. The consultant doesn't gather new info, but instead analyzes the brief, identifies hidden patterns, and forms a well-reasoned conclusion.
Together, Gather + Think = Understanding. This revised structure should provide a much smoother on-ramp for readers unfamiliar with neural networks.