Why Tokenization Affects Cost, Performance, and Accuracy
You've got the basics—now, why obsess over tokenization as engineers? It's not just theory; it hits your wallet, speed, and results. Let's unpack gradually.
-
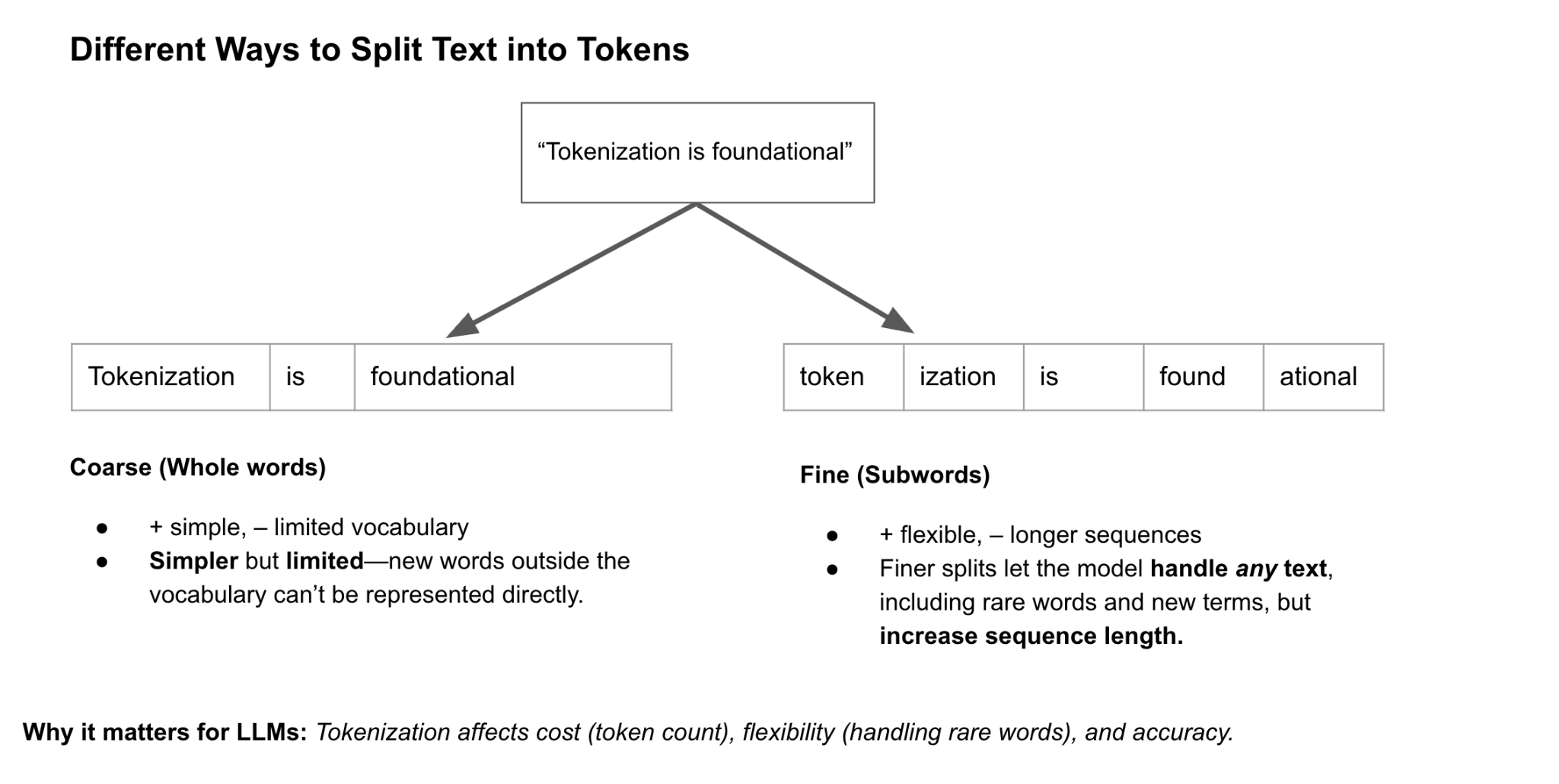
The Big Picture: Tokenization turns text into countable units. More tokens = more work for the LLM. It's like packing a suitcase: How you break down and pack affects everything.
-
Cost: APIs charge per token (input + output). Inefficient tokenization bloats the bill if you are a model hosting company.
- Example: "Tokenization is foundational" → 3 tokens (["Tokenization", "is", "foundational"]) vs. 5 (["Token", "ization", "is", "found", "ational"]). Companies as a result need to choose wisely to save cash!
-
Performance (Speed & Context): Models have a "context window" (max tokens they handle at once). Inefficient tokens fill it faster, slowing things down or forcing cuts.
- Analogy: Suitcase limit—overpack, and you leave stuff behind. Efficient tokens let you fit more meaning, enabling longer chats or complex tasks without lag.
-
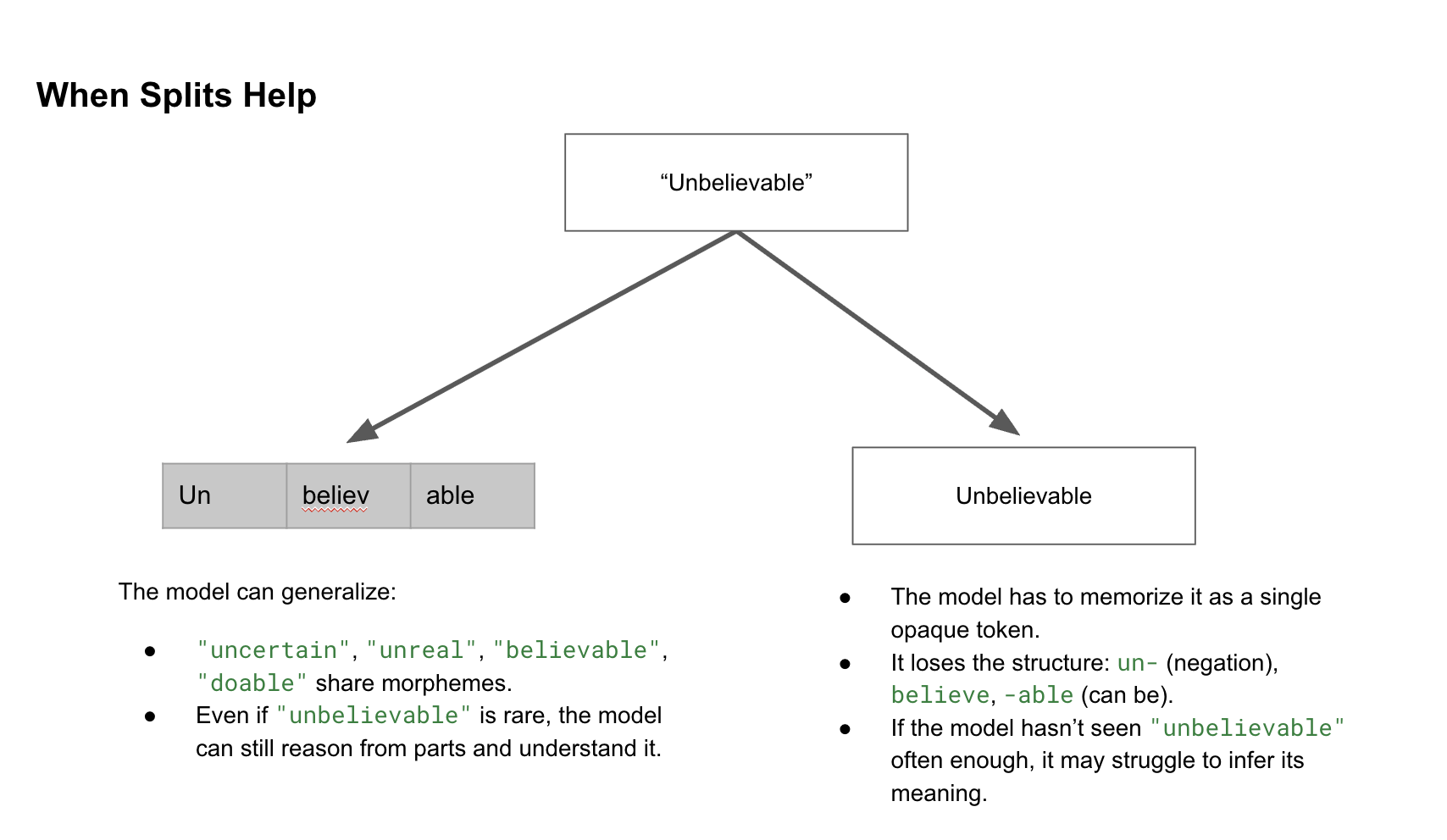
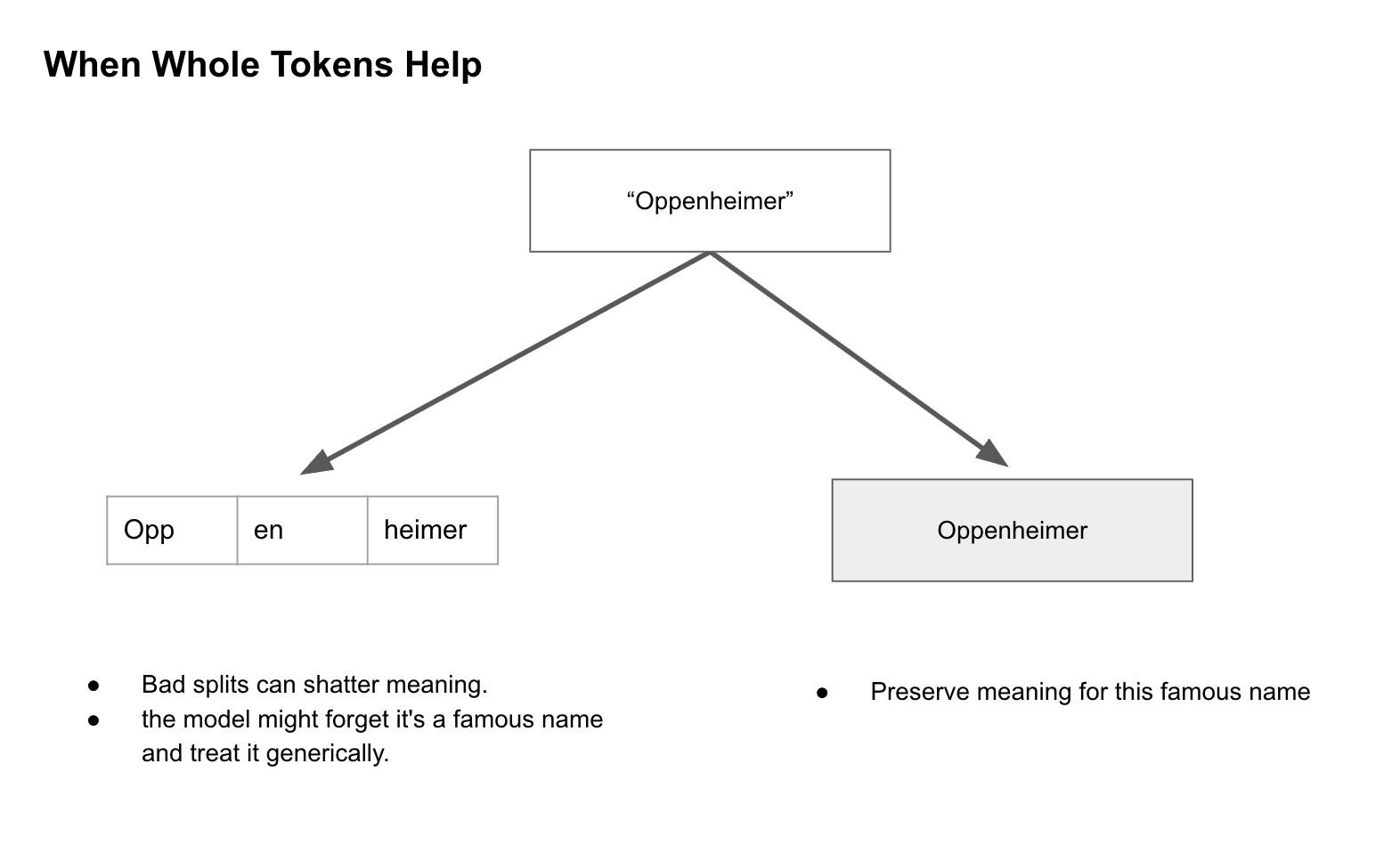
Accuracy: Bad splits can shatter meaning.
-
Example: In code, "!=" (not equal) split into "!" and "=" loses the concept. Or "Oppenheimer" as ["Opp", "en", "heimer"]—the model might forget it's a famous name and treat it generically.
-
Good tokenization preserves semantics, leading to smarter, more reliable outputs. Clean text reduces tokens without losing info, boosting fits and focus.
-

Engineer Perspective: Tokenization is like the currency of compute—models charge by tokens. If tokens are too fine-grained, costs go up and timeouts are more likely. If too coarse, you risk losing meaning and accuracy. Striking the right balance is key to efficient, reliable systems.