Putting It All Together: The Full Flow
Let's zoom out and trace the journey of a sentence from raw text to a state of deep understanding, summarizing everything we've covered.
Step 1: Preparing the Input
Before the main processing begins, the text is prepared.
- Tokenization & Embedding (Module 2): The sentence is broken into tokens, and each token is converted into a numerical vector called an embedding.
- Positional Encoding: A special "position stamp" vector is added to each embedding. This is crucial because it gives the model a sense of the original word order.
Step 2: Core Processing Through N Layers
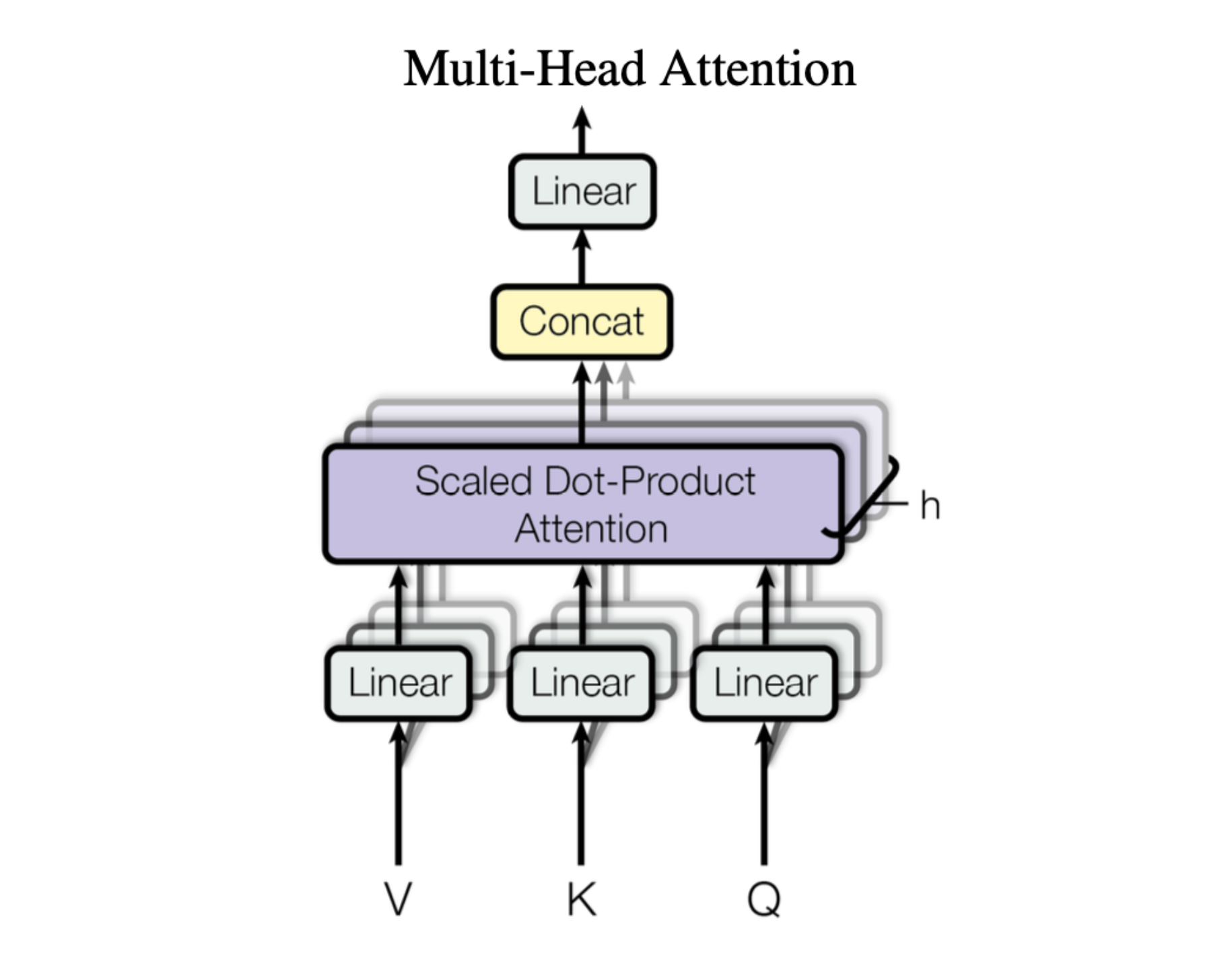
The prepared vectors are then sent through a deep stack of Transformer Blocks (e.g., 96 layers for GPT-3). This is where the magic happens. In every single block, the vectors undergo a two-part refinement:
- Attention (The Gathering Step): The Attention mechanism scans all the other words in the sequence to gather relevant context for each word.
- Feedforward (The Thinking Step): The Feedforward Network then processes this new, context-rich information for each word individually, allowing the model to "think" about what it has gathered.
Step 3: The Result
After passing through the entire stack of layers, the final output is a set of highly refined vectors. Each vector now represents its original word but is deeply enriched with contextual understanding from the entire sentence.
This architecture is the foundation for everything an LLM does. Now that we have these context-aware vectors, how do we use them to predict the next word? That’s exactly what we'll explore in the next module.
Checkpoint Questions
- The Context Problem Earlier machine learning models "read one word at a time and forget things." How does the Transformer's attention mechanism solve this problem, enabling each word to directly query and retrieve information from all other words based on relevance?
- The Order Problem Without positional encoding, the model wouldn't know word order—"The cat chased the dog" would be identical to "The dog chased the cat." How does positional encoding solve this problem?
- The Attention Mechanism in Action Using the example sentence "The rocket finally landed on its destination," explain how the Query (Q), Key (K), and Value (V) components work when the model processes the word "landed." What is it looking for, and how does it decide which other words are most relevant?
- Processing vs. Gathering Information The module distinguishes between the attention mechanism and feedforward layers. If attention is about "gathering information," what role do the feedforward layers play? Why do we need both?
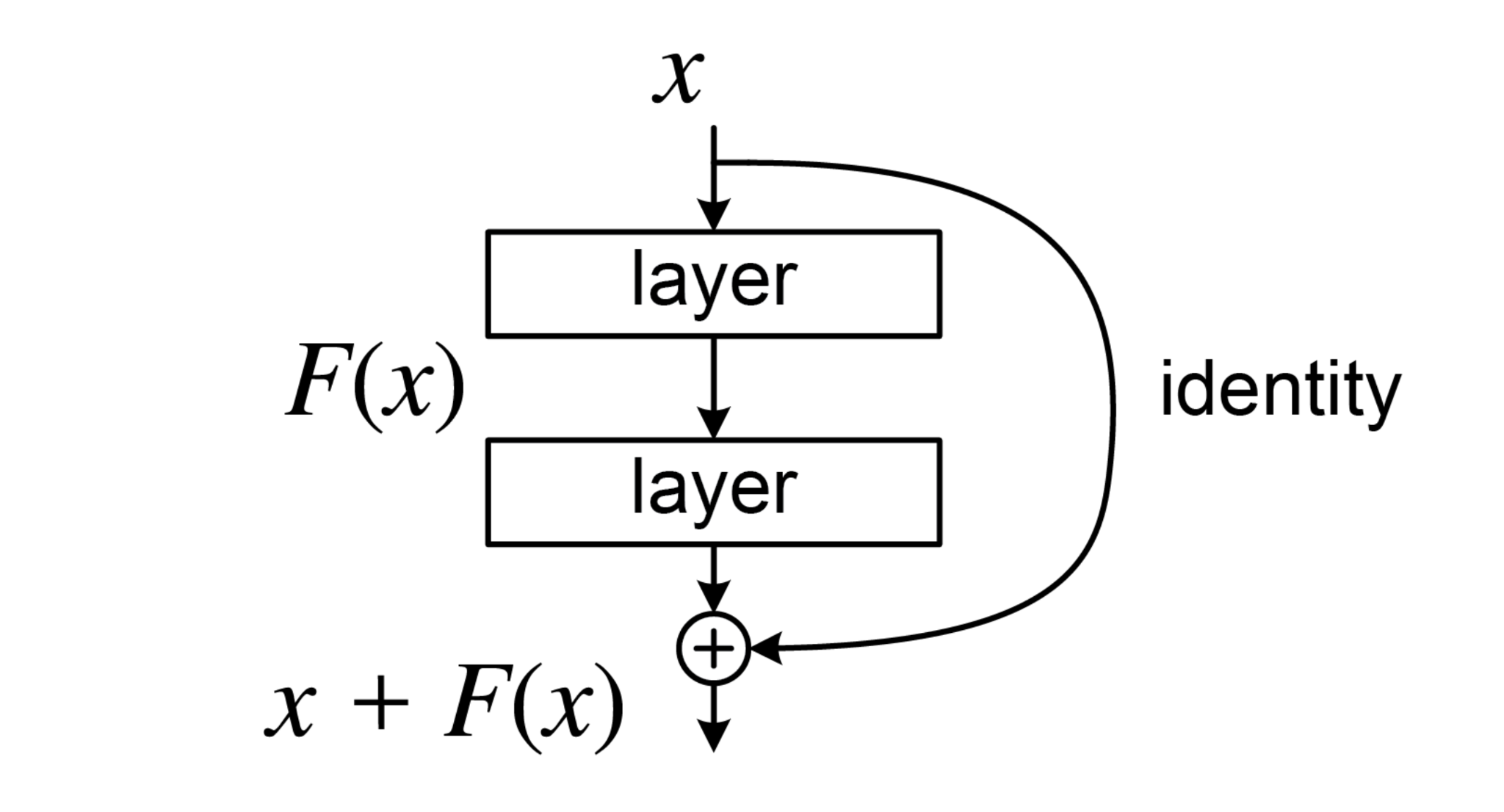
- Preventing Information Loss Residual connections prevent vanishing gradients and allow information to flow directly across layers. Using the "editor and document" analogy from the module, explain how they work and why they're crucial for training very deep models like GPT-3's 96 layers.
Fantastic progress! You've got the engine humming. Practice: How would attention handle "it" in our trophy example? Next module: From prompt to logits and sampling—how outputs get generated. Keep rocking!