Tokenization—The LEGOs of Language
Welcome back, class! We're powering through Module 2 of our 10-module quest to make you AI-native software engineers. If you nailed Module 1, you now know LLMs are like universal apprentices predicting the next word on a massive scale. Awesome! But how do they actually "see" and process language? That's where we dive in today: the building blocks—tokenization and embeddings.
We'll assume zero prior knowledge, starting from scratch and building step by step with fun analogies (like LEGOs and maps) to make it stick. By the end, you'll understand how text gets prepped for LLMs, why these steps matter, and how they impact your future AI projects. Think of this as fueling our rocket ship: Without breaking down the fuel (text) into usable parts, we can't launch. Let's get building!
Tokenization—The LEGOs of Language
Ever tried building a toy car from a single giant block of plastic? Nope—it's impossible. You need small, snap-together pieces to create something cool. That's exactly why LLMs can't just swallow whole sentences or books. They need text broken into bite-sized chunks called tokens.
From first principles, let's start simple:
-
The Basics: Tokenization is the process of splitting text into smaller units that the model can handle. At its simplest, it's like chopping a sentence by spaces.
- Example: "The unhappy cat sat on the mat." → ["The", “un”, “happy”, "cat", "sat", "on", "the", "mat."]
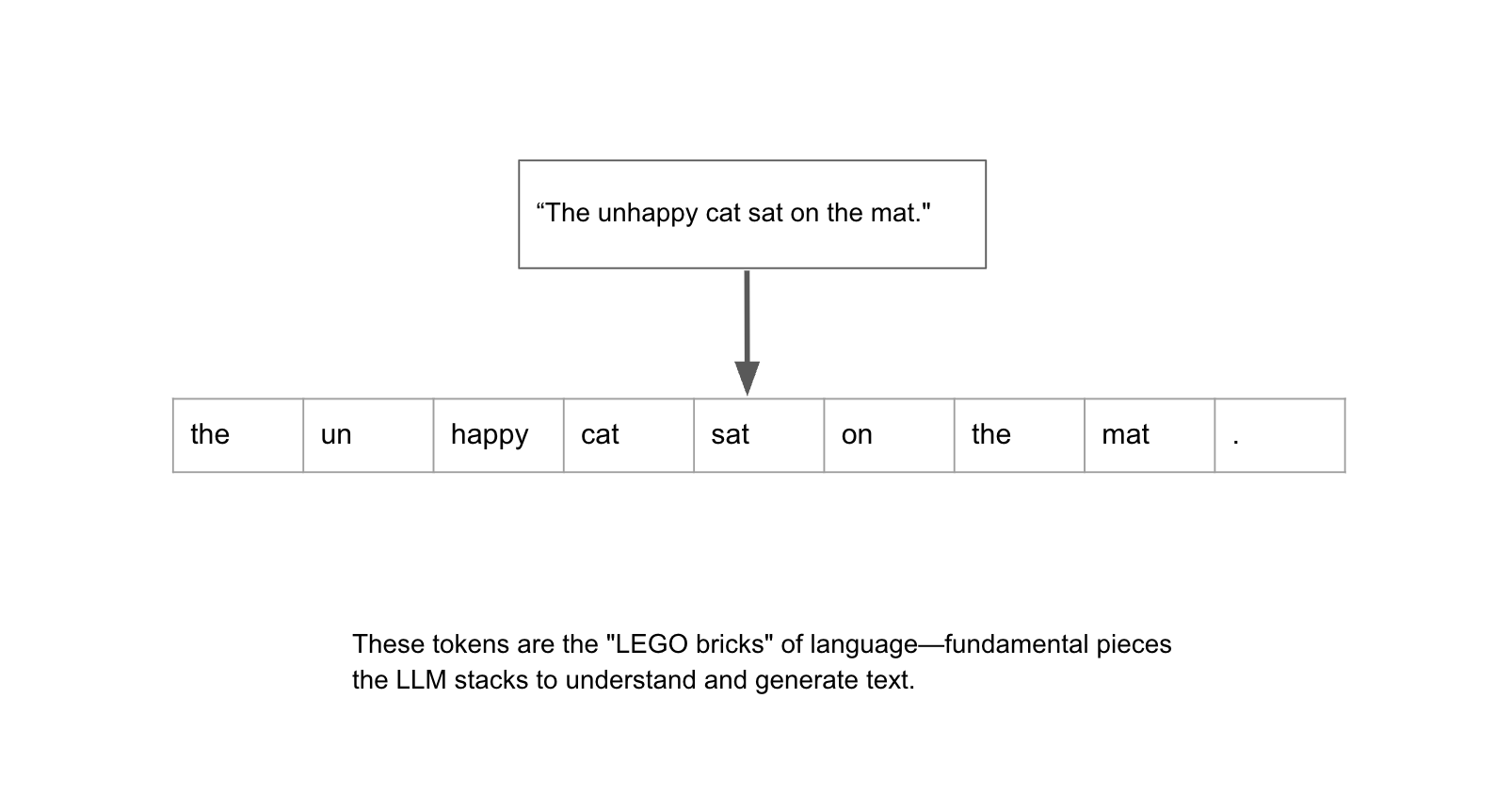
-
Why Not Whole Words?: Real language is messy. Words like "unhappiness" could be one big token, but smarter tokenizers (used in modern LLMs) break it down: ["un", "happi", "ness"].
- Gradual Build: "Un" often means "not" (like unhappy). "Ness" turns adjectives into nouns (like happiness). By learning these parts separately, the model gets reusable pieces. See a new word like "unfriendliness"? No problem—it recognizes "un" + "friendli" + "ness" and guesses the meaning, even if it's brand new.
-
How It Works: Tokenizers use rules or learned patterns to decide splits—whole words for common ones, subwords for rare or complex stuff. This makes the model efficient and flexible.

Analogy Time: Imagine assembling a puzzle. If pieces are too big (whole paragraphs), you can't connect them. Break into tokens (small pieces), and suddenly you can build anything—a story, code, or poem.
Quick Check-In: New to this? Tokens are just text chunks, and they are what LLMs really see. Start there, and we'll layer on why they're gold for LLMs.