Key Takeaways and Teaser for Next
Takeaways
-
Tokenization: This is the process of breaking raw text into smaller building blocks, called tokens. These tokens can be whole words, subwords, or even single characters. Think of them like LEGO pieces—small reusable parts that make it easier for the model to process text of any kind.
-
Embeddings: Once we have tokens, each one is mapped into a numerical vector. These vectors live in a high-dimensional “meaning space” where the distance between two vectors reflects how similar their meanings are. This allows the model to do useful “semantic math,” such as recognizing that king – man + woman ≈ queen.
-
Impact: The way we tokenize has a big effect on model performance. Efficient tokenization reduces the total number of tokens (cutting compute cost), helps the model handle more context within its memory window, and improves accuracy by representing language consistently.
What We Covered in This Module
-
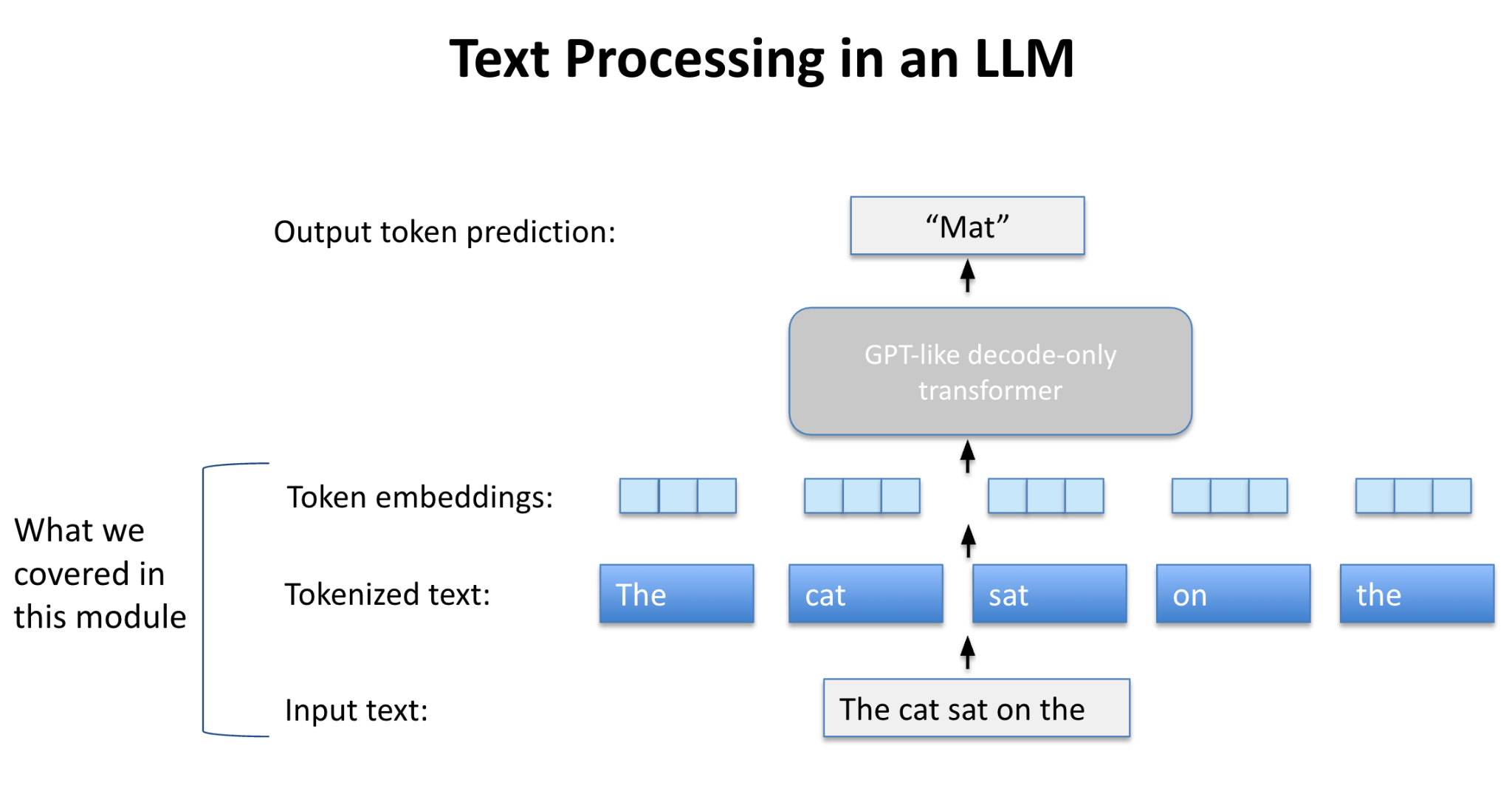
Input Text: We begin with natural language, such as the sentence “The cat sat on the”.
-
Tokenization: The input is split into smaller parts that the model understands, for example: The | cat | sat | on | the. This makes text manageable for computation.
-
Token Embeddings: Each token is transformed into a vector of numbers. These embeddings are not arbitrary—they capture meaning, so that related words or subwords have vectors that are close together in this semantic space.

Why It Matters
You can think of this as preparing the fuel that powers the LLM engine. Without tokenization and embeddings, the transformer would have no way to represent or reason about human language. These steps transform text into a mathematical form the model can work with.
Solid work, team! You've prepped the fuel for our LLM engine. Practice by tokenizing a sentence manually—what subwords would you choose? Next module: Transformer architecture—how attention makes LLMs context-aware. Buckle up; it's getting exciting!
Close
3 truths.
- Tokens are the unit that models bill and process.
- Embeddings turn language into geometry, so similarity becomes distance.
- Better token hygiene improves cost, speed, and often accuracy because more relevant context fits.
Success for the class
- I can explain what a token is and why token counts matter for cost and latency.
- I can demonstrate how truncation drops information and how to keep critical facts inside the window.
- I can describe embeddings as vectors and use cosine similarity to compare them.
- I can read a simple plot of an embedding space and predict which words will be near each other.